Designing Data Intensive Applications - Chapter # 1
Data intensive applications
Basic functionalities for data intensive applications include databases, caches, search indexes, stream processing and batch processing.
Thinking about Data Systems
Different categories of tools such as databases, queues and caches are apparently very similar, but have very different structures and functionalities.
Hence different performance and implementations. For instance, Redis and Kafka are both message queues but serve for very different use cases. However, the determination for use cases of such tools has somewhat become vague.
Also, with the increase in number of applications and requirements, work is divided into smaller tasks which are stitched together into code bases.
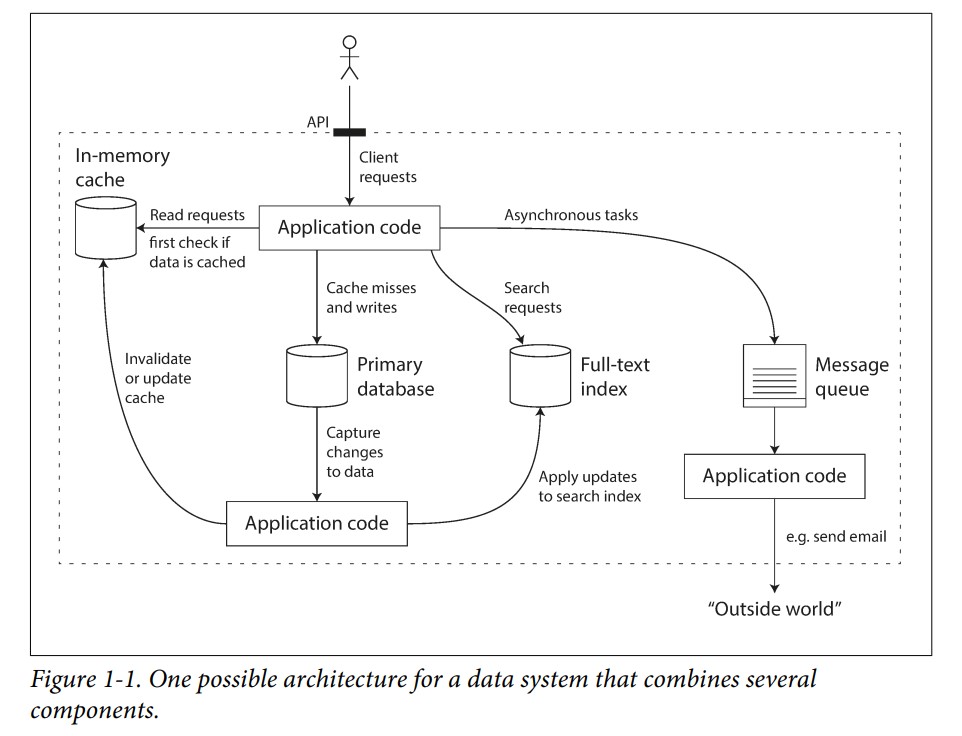
Often APIs (Application Programming Interface) hides all the working and implementation of a system from the end user or client.
Focus of the book
There are three concerns which are important for most software systems.
Reliability\n
Scalability\n
Maintainability\n
Reliability
The system should continue to work correctly (performing the correct function at the desired level of performance) even in the face of adversity (hardware or soft‐ware faults, and even human error).
So, a system can be reliable, if it is working correctly even when something goes wrong. There is a different between fault and failure.
A system can be faulty when it's components do not perform intended tasks correctly. Whereas a failure causes the whole system stops providing the required service.
It's impossible to reduce the probability of faults to zero.
There are different types of faults.
Hardware faults, Software errors, Human faults.
It is worth mentioning that one study of large internet services found that human operators are leading cause of outages compared to 10%-25% of outages by hardware faults.
Scalability
As the system grows (in data volume, traffic volume, or complexity), there should be reasonable ways of dealing with that growth.
A reliable system today can be an unreliable system tomorrow. Therefore, scalability plays a key role in a system which is to take increasing amount of load.
There are several perimeters to define load and handle it accordingly. Sometimes one approach works, sometimes another, and often a hybrid approach is established to achieve the indented result.
Approaches for Coping with Load
Vertical Scaling -> Employing powerful machine to do a task
Horizontal Scaling -> Distributing work load across smaller machines
Elastic systems are for increasing resources automatically when work load is increased. Such systems are preferred when the load is unpredictable.
However, manually scaled systems are less complex.
Maintainability
Over time, many different people will work on the system (engineering and operations, both maintaining current behavior and adapting the system to new use cases), and they should all be able to work on it productively.
Apart from development of a system, majority of its cost comes from maintenance.
To avoid problematic maintenance of legacy software systems, three design principles are discussed:
Operability
Make it easy for operations teams to keep the system running smoothly
Simplicity
Make it easy for new engineers to understand the system, by removing as much complexity as possible from the system. (Note this is not the same as simplicity of the user interface.)
Evolvability
Make it easy for engineers to make changes to the system in the future, adapting it for unanticipated use cases as requirements change. Also known as extensibility, modifiability, or plasticity.